RNN(Recurrent Neural Network:再帰型ニューラルネットワーク):時系列データの学習を支える仕組み

RNNとは?
RNNは時系列データや文章のように「順序が重要なデータ」を扱うためのニューラルネットワークです。
通常のニューラルネットワーク(全結合層など)は「入力 → 出力」で一度きりの変換をしますが、RNNは過去の情報を「記憶」しながら次の処理に活かすことができます。
仕組みのイメージ
RNNは、入力データを順番に1つずつ処理しながら、内部に「隠れ状態(hidden state)」を持つ構造となっていて、次のようなループの構造を持っています。
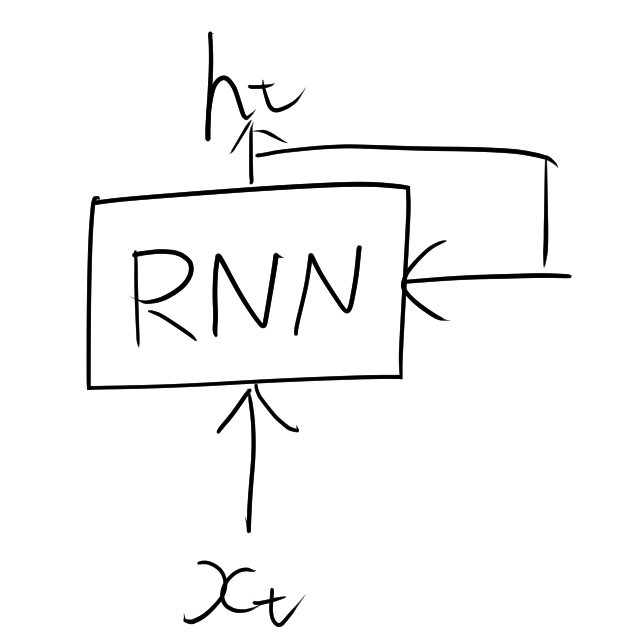
処理の流れを文章を例にすると、
入力1: 「私は」 → 出力1 & 状態更新
入力2: 「昨日」 → 出力2 & 状態更新(「私は」の情報を保持)
入力3: 「映画を」 → 出力3 & 状態更新(前の単語の文脈を反映)
...
RNNの基本構造
RNNは、時刻 $t$ の入力 $\mathbf{x}_t$ を受け取り、前の時刻の隠れ状態 $\mathbf{h}_{t-1}$ と組み合わせて新しい隠れ状態 $\mathbf{h}_t$ を計算します。数式は次の通りです。
- $\mathbf{x}_t$:時刻 $t$ の入力ベクトル
- $\mathbf{h}_t$:時刻 $t$ の隠れ状態(記憶)
- $\mathbf{y}_t$:時刻 $t$ の出力
- $W_x, W_h$:学習される重み行列
- $\mathbf{b}$:バイアス項
- $f$:活性化関数(例:$\tanh$)
では、次にRNNの学習に欠かせない BPTT(Backpropagation Through Time) と Truncated BPTT について、解説します。
BPTTとは?
BPTTは、RNNの誤差逆伝播を時間方向にも展開して計算する方法です。 通常のニューラルネットは層の方向に誤差を逆伝播しますが、RNNは時間方向に繋がっているため、それに合わせた逆伝播を行います。
問題点
BPTTを全時刻に対して行うと
- 計算コストが高い(長い系列ほどメモリも計算量も増える)
- 勾配消失・勾配爆発が起こりやすい
Truncated BPTT(TBPTT)
これらの問題を緩和するために使われるのが Truncated BPTT です。 一定の長さ $k$ だけ時間方向に逆伝播する方法で、過去すべてではなく、直近の情報だけを使って勾配を計算します。注意点として逆伝播を分割しているだけで、順伝播の分割はしていません。
手順例
- 系列を長さ $k$ ごとのチャンクに分割
- 各チャンクで順伝播
- 各チャンクの範囲内だけで逆伝播(BPTT)
- 次のチャンクに移るときは、隠れ状態は引き継ぐが勾配はリセット
数式イメージ
もし系列長 $T=100$、$k=20$ なら、 BPTTは
$$ t \in [1,100] \quad 全部逆伝播 $$
ですが、TBPTTでは
$$ t \in [1,20], [21,40], [41,60], \dots $$
のように分けて、その範囲だけで
$$ \frac{\partial \mathcal{L}}{\partial \mathbf{h}_t} $$
を計算します。
RNNの得意分野
- 文章生成(次の単語を予測)
- 音声認識(音の波形を順番に処理)
- 株価予測(時系列データ)
- 機械翻訳(文の構造を理解しながら変換)
RNNの課題
RNNには長期的な依存関係が苦手という欠点があります。
- 文の最初の情報が、後半になると薄れてしまう
- 逆に値が爆発してしまう
このため、実用ではLSTMやGRUといった改良版がよく使われます。
これらは「ゲート構造」を使って、重要な情報を長く保持できます。





