本ページはプロモーション(PR)が含まれています
更新日: 2024/09/18
scikit-learnのロジスティック回帰の使い方について

はるか
ロジスティック回帰って、どういうアルゴリズムか知ってる?
ふゅか
もちろん!ロジスティック回帰は、分類問題を解くためのアルゴリズムだよ。主に分類問題、例えばスパムメールかどうかを判定するのに使われるの。
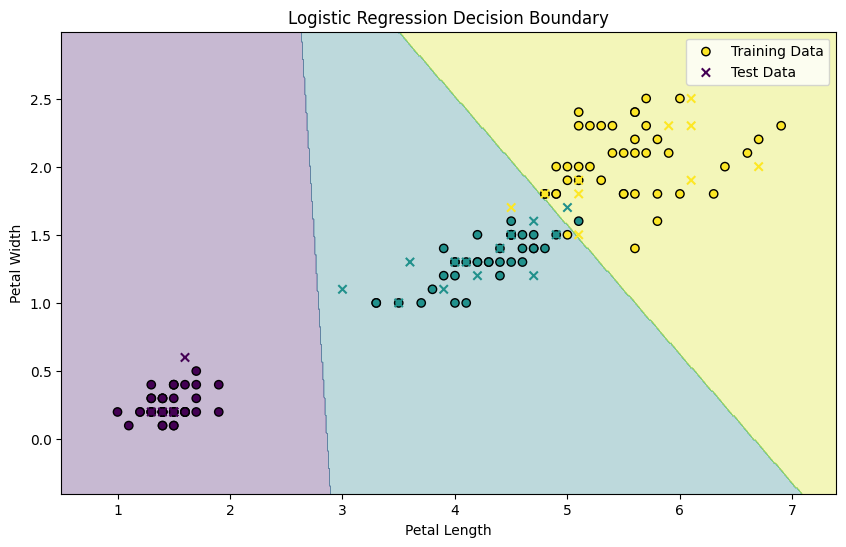
ロジスティック回帰の概要
scikit-learnのロジスティック回帰は、分類問題を解くためのアルゴリズムです。
- 目的: ロジスティック回帰は、主に二値分類(例えば、スパムメールかどうかの判定)に使用されます。ただし、マルチクラス分類にも対応しています。
- 決定境界: ロジスティック関数(シグモイド関数)を使って、予測結果を0と1の間の確率に変換します。この確率を閾値(通常は0.5)で分類します。
Scikit-learnでの実装方法
Scikit-learnを使ってロジスティック回帰を実装するには、以下の手順で行います。
- ライブラリのインポート: 必要なモジュールをインポートします。
- データの準備: トレーニングデータとテストデータを準備します。
- モデルの作成と学習: ロジスティック回帰モデルを作成し、データに適合させます。
- 予測と評価: モデルを使って予測を行い、その性能を評価します。
ふゅか
それから、モデルを使って予測して、その性能を評価するのよね。Scikit-learnだと結構簡単にできるの。
はるか
例えば、Irisデータセットを使ってモデルを学習させる。
実装例
Scikit-learnでのロジスティック回帰の基本的な実装例を示します。
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# データの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=142)
# ロジスティック回帰モデルの作成と学習
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# モデルの精度を評価
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}') モデルの精度は次のようになります。
モデルの精度は次のようになります。

y_predの中身を確認すると次のようになります。

解説
- データセット: ここでは、
load_iris()を使って有名なIrisデータセットを読み込んでいます。 - データ分割:
train_test_splitでデータをトレーニングセットとテストセットに分割します。 - モデル作成と学習:
LogisticRegressionを使ってモデルを作成し、fitメソッドで学習させます。max_iterは最大反復回数で、収束しない場合にこれを増やすことができます。 - 予測と評価: テストデータを使って予測を行い、
accuracy_scoreで精度を評価しています。





