本ページはプロモーション(PR)が含まれています
更新日: 2025/01/17
scikit-learnにおけるDBSCANの使い方と意味について

はるか
DBSCANって知ってる?
ふゅか
もちろん!密度に基づくアルゴリズムで、特殊な形のクラスタを見つけることができるのよね!
DBSCANとは?
データ分析や機械学習を行う際、データをグループ化する「クラスタリング」という手法は非常に重要です。その中で「DBSCAN(Density-Based Spatial Clustering of Applications with Noise)」というアルゴリズムは、特に密度に基づいたクラスタリングを得意とする手法です。
DBSCANとは?
DBSCANは「密度」に基づいてデータをクラスタリングするアルゴリズムです。一般的なクラスタリング手法(例:K-means)とは異なり、クラスタの形状や数を事前に指定する必要がありません。
DBSCANの主な特徴:
- 高密度なデータをクラスタとして検出
データが密集している領域をクラスタとして定義します。 - ノイズ点を識別
密度が低いデータ点(ノイズ)はクラスタに含めず、独立した「孤立点」として扱います。
DBSCANの仕組み
DBSCANには2つの重要なパラメータがあります。
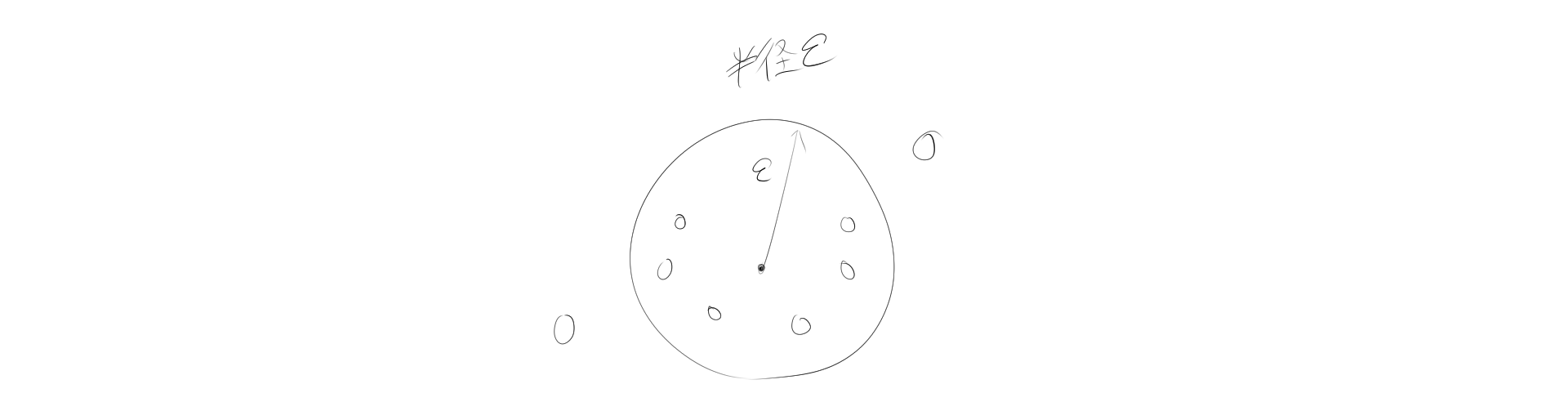
- eps(ε: エプシロン)
データ点同士の距離を測る基準。この距離以内に十分多くの点が存在する場合、その点はクラスターのコアになります。円でクラスターかどうか判定する場合は半径をεとして次のようになります。
- min_samples
1つのクラスタを形成するために必要な最小データ数。この値が小さいとノイズが減りますが、クラスタが不安定になる可能性があります。
scikit-learnを使ったDBSCANの実装
Pythonのscikit-learnライブラリでは、DBSCANは簡単に使用できます。
必要なライブラリのインストール
まず、scikit-learnがインストールされていない場合は以下のコマンドを実行してください。
pip install scikit-learn
コード例
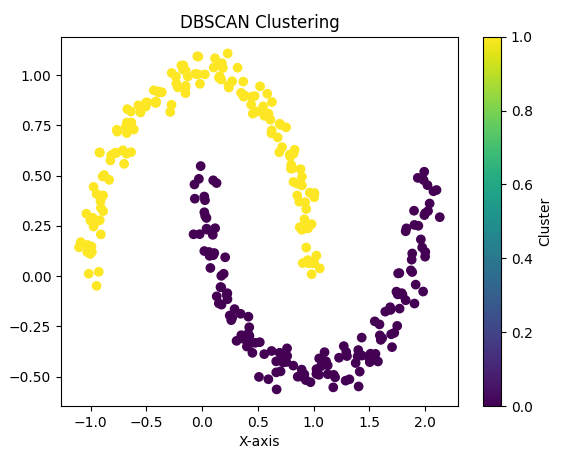
以下は、サンプルデータを使ってDBSCANを実装する例です。
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# サンプルデータの作成
X, _ = make_moons(n_samples=300, noise=0.05, random_state=42)
# DBSCANによるクラスタリング
dbscan = DBSCAN(eps=0.2, min_samples=5)
labels = dbscan.fit_predict(X)
# 結果をプロット
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title("DBSCAN Clustering")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.colorbar(label='Cluster')
plt.show()- データ生成
make_moons関数を使い、月のような形をしたサンプルデータを作成します。 - DBSCANの実行
DBSCAN(eps=0.2, min_samples=5)でアルゴリズムを初期化し、fit_predictメソッドでクラスタリングを実行します。 - 結果の可視化
plt.scatterを使ってクラスタリングの結果をプロットします。c=labelsを指定することで、クラスタごとに異なる色で表示します。