本ページはプロモーション(PR)が含まれています
更新日: 2024/12/08
【scikit-learn】k近傍法(k-NN)の使い方と意味について

はるか
k近傍法って、知ってる?
ふゅか
うん!新しいデータがどのグループに属するかを予測するアルゴリズムよね。シンプルだけど効果的!
はるか
そう、分類アルゴリズムの一つ。近いデータを見ることがポイント。
k近傍法
k近傍法(k-NN)とは?
k近傍法(k-Nearest Neighbors, k-NN)は、機械学習のアルゴリズムの一つです。このアルゴリズムは、「新しいデータがどのクラスに属するか」を分類されたデータを基に予測します。
アルゴリズムの流れ
- 訓練データを用意します(ラベル付きのデータ)。
- 距離が近いデータ(「近傍」と呼びます)をk個選びます。このkは、事前に設定する整数値が用いられます。
- k個の近傍の中で、最も多いカテゴリ(ラベル)をデータの分類結果とします。
例えば、k=5のとき、真ん中の白い点のラベルをk近傍法を利用して推測します。
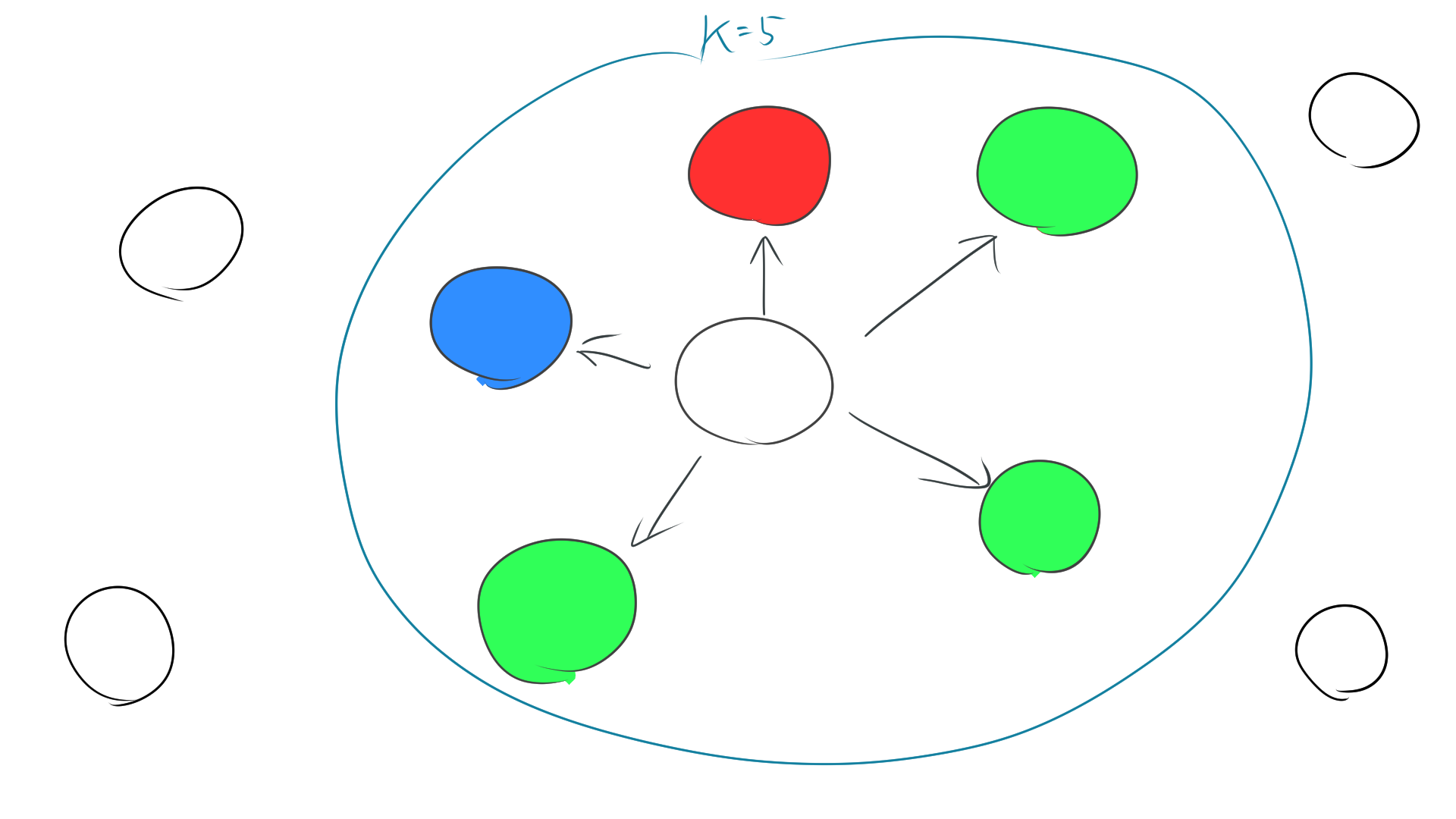
この場合、距離が近いデータ点はそれぞれ
青:1個、赤:1個、緑:3個
となるので、多数決で緑がラベルとして推測されます。
ふゅか
例えば、k=5なら、近くにいる5つのデータを見るんだよね。その中で、一番多いグループを新しいデータのラベルにするの!
はるか
多数決の仕組み。緑が3個で一番多い。だから、緑になる。
Scikit-learnでの実装
Scikit-learnはPythonで使用される機械学習ライブラリで、k-NNを簡単に実装できます。以下は基本的な流れです。
必要なライブラリをインポート
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
データの準備
ここでは有名なtoyデータセットであるIrisデータセットを使用します。このデータセットには、アヤメの品種(Setosa, Versicolor, Virginica)の特徴データが含まれています。
# データをロード
iris = load_iris()
X = iris.data # 特徴量
y = iris.target # ラベル(品種)
# データを訓練用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
モデルの構築と訓練
Scikit-learnでは、KNeighborsClassifierクラスを使用します。ここでkの値(近傍数)を指定します。
# k-NNモデルを作成
k = 3 # 近傍数
knn = KNeighborsClassifier(n_neighbors=k)
# モデルを訓練
knn.fit(X_train, y_train)
テストデータでの予測
訓練が終わったら、テストデータに対して予測を行います。
# 予測
y_pred = knn.predict(X_test)
# 正解率を計算
accuracy = accuracy_score(y_test, y_pred)
print(f"正解率: {accuracy * 100:.2f}%")

距離の計算方法
metricを指定することで、データ間の距離を計算する方法を指定できます(デフォルトはユークリッド距離)。
# 他の距離計算を使用
knn = KNeighborsClassifier(n_neighbors=3, metric='manhattan') # マンハッタン距離マンハッタン距離を利用すると、

はるか
デフォルトはユークリッド距離。
ふゅか
だけど、データに応じてマンハッタン距離や他の方法も使えるんだよね!





