本ページはプロモーション(PR)が含まれています
更新日: 2024/12/09
Scikit-learnによるグリッドサーチとハイパーパラメータチューニングについて

目次
はるか
ハイパーパラメータって知ってる?モデルを制御する設定だけど、何を選ぶかで精度が変わる。
ふゅか
もちろん!決定木の深さやSVMの正則化パラメータとかね。調整次第でモデルの性能がグッと上がるんだよね!
グリッドサーチとハイパーパラメータチューニング
機械学習モデルの精度を向上させる上で、ハイパーパラメータチューニングは欠かせません。ハイパーパラメータとは、学習プロセスを制御するために設定される外部から指定するパラメータのことです。一方で、モデル内部で自動的に調整されるパラメータ(例:重み)とは異なり、ハイパーパラメータは事前に選ぶ必要があります。
この記事では、Pythonの機械学習ライブラリScikit-learnを使って、効率的にハイパーパラメータを調整する方法、特にグリッドサーチを使った手法について解説します。
ハイパーパラメータとは?
ハイパーパラメータは、モデルの性能やトレーニングプロセスに影響を与える重要な要素です。例を挙げると、
- 決定木:
max_depth(木の深さ)、min_samples_split(ノードを分割するための最小サンプル数) - SVM:
C(正則化パラメータ)、gamma(カーネルの係数) - k-NN:
n_neighbors(近隣点の数)
これらの値を適切に選ぶことで、モデルの過学習や過小適合を防ぎ、予測性能を向上させられます。
グリッドサーチとは?
グリッドサーチ(Grid Search)は、ハイパーパラメータの候補を網羅的に探索する方法です。具体的には、次の手順で進行します。
- ハイパーパラメータの候補を設定
例えば、C=[0.1, 1, 10]、gamma=[0.001, 0.01, 0.1]のように複数の値を用意します。 - 全ての組み合わせを試す
各候補の組み合わせについてモデルを訓練し、性能を評価します。 - 最も良い結果を得た組み合わせを選択
予測精度やスコアが最高となるパラメータを採用します。
Scikit-learnでのグリッドサーチの実装
Scikit-learnでは、GridSearchCVを使って簡単にグリッドサーチを行うことができます。以下に、SVMを例にしたコードを示します。
必要なライブラリのインポート
まず、グリッドサーチに必要なライブラリをインポートします。GridSearchCVはモデルのハイパーパラメータ探索をサポートし、SVCはサポートベクターマシンをサポートしています。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
データの準備
scikit-learnに標準で含まれるtoyデータセットであるIrisデータセットをロードして使用します。
# データセットのロード
iris = load_iris()
X, y = iris.data, iris.target
ハイパーパラメータの設定
グリッドサーチでは、試したいパラメータの候補をあらかじめ定義します。
# 試すパラメータの候補
param_grid = {
'C': [0.1, 1, 10],
'gamma': [0.001, 0.01, 0.1],
'kernel': ['rbf']
}
グリッドサーチの実行
次に、GridSearchCVを用いてグリッドサーチを設定し、モデルの学習を行います。
# モデルとグリッドサーチの設定
grid_search = GridSearchCV(SVC(), param_grid, cv=5, scoring='accuracy')
# モデルの学習
grid_search.fit(X, y)
結果の確認
グリッドサーチの結果を確認することで、最適なパラメータやそのときのスコアを取得できます。
# 最良のパラメータ
print("Best Parameters:", grid_search.best_params_)
# 最良のスコア
print("Best Score:", grid_search.best_score_)
# 各組み合わせの結果を表示
print("Grid Scores:")
for mean, params in zip(grid_search.cv_results_['mean_test_score'], grid_search.cv_results_['params']):
print(f"{params}: {mean:.3f}")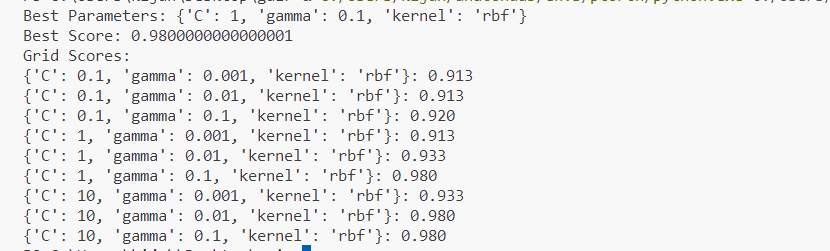
はるか
最良のパラメータはgrid_search.best_params_で取得。
ふゅか
スコアもgrid_search.best_score_でチェックできるよ!各組み合わせの結果も見れるから、どのパラメータがどのくらい良かったか比較できるね。





