機械学習・ディープラーニング
-
【Transformers】SwallowをHugging Faceで使う方法

Swallowとは? 産業技術総合研究所(産総研)と東京工業大学の研究チームは、「Swallow」という日本語に特化した大規模言語モデルを2023年12月19日に公開しました。このモデルは、米Meta …
-
スパコン「富岳」で学習したFugaku LLMをHugging Faceからダウンロードして使う方法

Fugaku LLMとは? Fugaku-LLMは、日本のスーパーコンピュータ「富岳」を活用した大規模言語モデルです。このモデルは、特に日本語の自然言語処理において高い性能を発揮することが期待されてい …
-
PythonのTransformersライブラリでできること!pipelineの使い方について解説!

PythonのTransformersとは? PythonのTransformersライブラリは、自然言語処理(NLP)のタスクを簡単に、効率的に処理するためのツールです。このライブラリは、Huggi …
-
シグモイド関数と微分・グラフについて
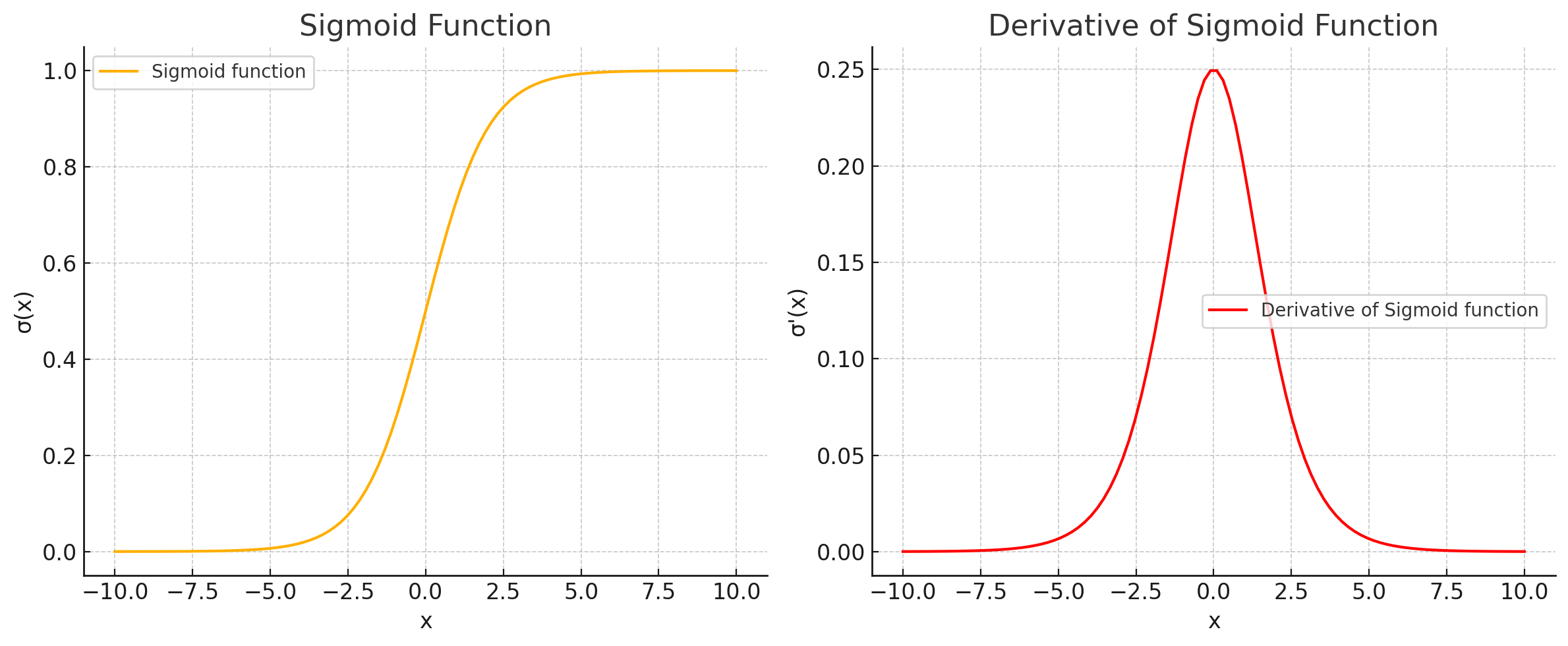
シグモイド関数 シグモイド関数の微分 シグモイド関数 \(\sigma(x)\) の微分を商の微分の規則を使って計算します。まず、商の微分に従って微分します。商の微分の公式は以下の通りです。 \[ \ …
-
PyTorchにおけるモデルの保存と読み込み!2つの方法

PyTorchにおけるモデルの保存と読み込み PyTorchは、深層学習モデルの開発や学習に使用されているフレームワークです。PyTorchで、学習したモデルをデータを保存する方法は大きく分けて二つあ …
-
UCS(均一コスト探索)について解説!経路探索の例付き
UCSとは? UCSとは日本語で均一コスト探索と呼ばれる、経路探索のアルゴリズムである。UCSはbest-first search(最良優先探索)の一種と考えることができる。best-first se …
-
Bayesian Networksのd-separation
Bayesian Networks(ベイジアンネットワーク)のd-separation(分離)について解説します。 1.d-separationとは? d-separationはベイジアンネットワーク …
-
【PyTorch】Tensorの統計量、平均、分散、標準偏差について

統計量の計算 テンソル操作を行う際には、合計、平均、分散など、さまざまな統計量を計算することがよくあります。ここでは、PyTorchの便利なメソッドを使ってこれらの統計量を計算する方法を紹介します。 …